1.1 AI History
This section provides an overview of Artificial Intelligence, including its origins, core concepts, and goals.
To get started, here are some foundational resources that offer a general understanding before we delve deeper into specific areas.
AI is commonly said to have originated at the Dartmouth Conference in 1956, where leading thinkers gathered to discuss the possibilities of machine intelligence. While this event popularized AI, the concept of thinking machines dates back to the 1930s, with early work from pioneers like Alan Turing, John von Neumann, and Claude Shannon, who laid the groundwork for modern computing and artificial intelligence.
Rather than a detailed history, below is a timeline of key milestones in AI and links to more in-depth resources.
- Timeline of History of AI
- Wiki Page (I understand it is a wiki; however, most of the general ideas in it are accurate.)
- Should Read
1.2 Expert Systems
Before exploring modern AI, it's essential to understand the foundational work from the 1950s to 1980s that set the stage for today’s advancements. During AI's early years, much of the focus was on developing expert systems and logical reasoning frameworks. These systems, such as IBM's Deep Blue and other rule-based engines, were designed to simulate human expertise in specific domains, relying heavily on symbolic reasoning and decision rules.
- The following is one of the better sources for a Deep Dive into Expert Systems.
- Despite its age, this paper offers valuable insights. Early Expert Systems: Where Are They Now?



1.3 Machine Learning (ML)
Terms like Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) are often used interchangeably, but each has specific distinctions. Broadly speaking, machine learning can be thought of as a process of solving optimization problems. By adjusting parameters and learning from data, ML algorithms can identify patterns, make predictions, and support decision-making in a variety of contexts. Each approach to ML has its own strengths and biases, and some methods are better suited for specific types of problems.
The simplest way to categorize machine learning is by its approach to learning from data, also known as the learning paradigm. I will keep most of this short, sweet, and resource plentiful.
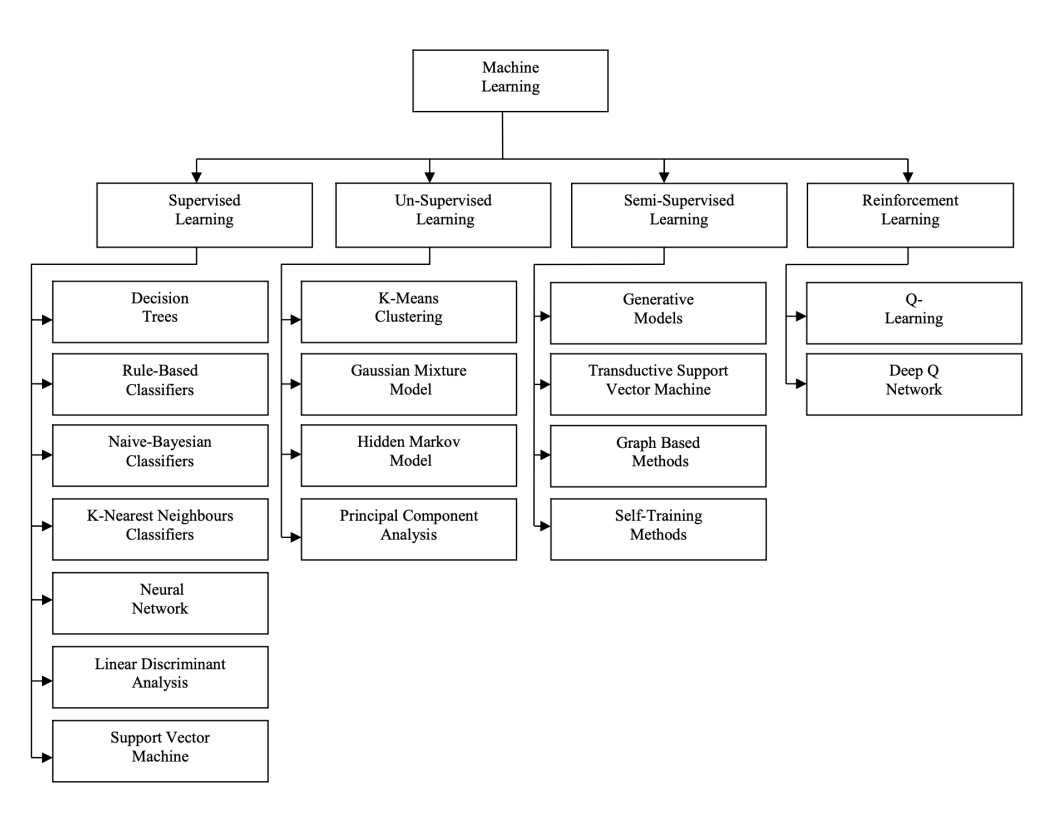
1.3.1 Supervised Learning
Supervised learning involves training an algorithm on a labeled dataset, where each data point includes both input features and the correct output (label). The algorithm makes predictions, calculates the error between its predicted output and the actual output, and then adjusts its internal parameters (weights) to minimize this error over time, improving its predictions.
Decision Trees
- Decision Trees are simple and powerful. The best solution to a problem is typically the simplest. Greate Example


Naive Bayes
Naive Bayes is a simple but powerful algorithm for classification tasks. It’s based on the assumption that features (like words in an email) are independent of each other, which makes it a “naive” approach. Despite its simplicity, it works well for many problems, including spam filtering.


Nearest Neighbor
The *k-Nearest Neighbor* algorithm is like asking your closest friends for advice. To make a prediction, it looks at the "k" closest data points in the dataset and classifies based on the majority of those neighbors. It’s simple, intuitive, and works well for many problems, but can be computationally expensive with large datasets.
- The following is one of the better sources for a Deep Dive into Expert Systems.
- Despite its age, this paper offers valuable insights. Early Expert Systems: Where Are They Now?


Artificial Neural Networks (ANN)
Artificial Neural Networks are the backbone of Deep Learning. These networks are inspired by the human brain, with layers of "neurons" that process information. They excel at recognizing patterns in large datasets, from images to natural language, and form the foundation for many cutting-edge technologies like facial recognition and language translation.



Support Vector Machines (SVM)
SVMs are like boundary setters. They aim to find the optimal boundary (or hyperplane) that best separates data into categories. The "support vector" refers to the data points that are closest to this boundary and help define it. SVMs are particularly powerful for complex classification tasks.
- Great Intro into support vector machines


1.3.2 Unsupervised Learning
Unsupervised learning involves training an algorithm on a dataset without labeled outputs. The model tries to learn the underlying patterns or structure in the data, which is particularly useful for tasks like clustering, anomaly detection, and dimensionality reduction.
k-Means Clustering
The *k-Means Clustering* algorithm groups data points into clusters based on their similarities. It works by partitioning the dataset into "k" clusters, assigning each data point to the cluster with the nearest centroid. This method is commonly used for customer segmentation and image compression.


Hierarchical Clustering
*Hierarchical Clustering* builds a hierarchy of clusters, which can be visualized using a tree-like diagram called a dendrogram. It’s useful when the number of clusters is unknown and provides insight into how clusters relate at various levels. This approach is often applied in social network analysis and gene expression data.

Principal Component Analysis (PCA)
*Principal Component Analysis (PCA)* is a dimensionality reduction technique that transforms data into a lower-dimensional space while preserving as much information as possible. It’s commonly used for reducing features in high-dimensional data for visualization or to improve model performance.


Anomaly Detection
*Anomaly Detection* algorithms identify unusual patterns or data points that deviate from the norm. These techniques are valuable in identifying fraud, defects, or faults in various domains, especially when anomalies occur infrequently.


Association Rule Learning
*Association Rule Learning* is used to discover interesting relationships or patterns within data, typically in transactional datasets. The Apriori and Eclat algorithms are two popular methods that help identify associations between items in large datasets, often applied in market basket analysis.


1.3.3 Semi-Supervised Learning
Semi-supervised learning is a technique where an algorithm is trained on a dataset that contains a small amount of labeled data and a larger amount of unlabeled data. This approach combines elements of supervised and unsupervised learning, leveraging the labeled data to guide the model in making predictions while learning from the structure within the unlabeled data.
Self-Training
- Self-training is one of the simplest and most intuitive semi-supervised learning methods. Detailed Overview


Co-Training
Co-training uses multiple views of the data to train separate models that teach each other. Each model makes predictions on unlabeled data, and their most confident predictions are used to create additional training data for the other models. This approach works particularly well when the different views of the data provide complementary information.
Generative Models
Generative models in semi-supervised learning learn the underlying

Graph-Based Methods
Graph-based methods utilize the structure within data points, representing them as nodes in a graph and using edges to indicate similarity. These methods spread labels through the graph, leveraging connections between labeled and unlabeled data to make predictions.

1.3.4 Reinforcement Learning (RL)
Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment, receiving rewards or penalties based on its actions. Over time, the agent learns to take actions that maximize cumulative reward, making RL particularly useful in scenarios like robotics, game playing, autonomous driving and lately for training LLMs.
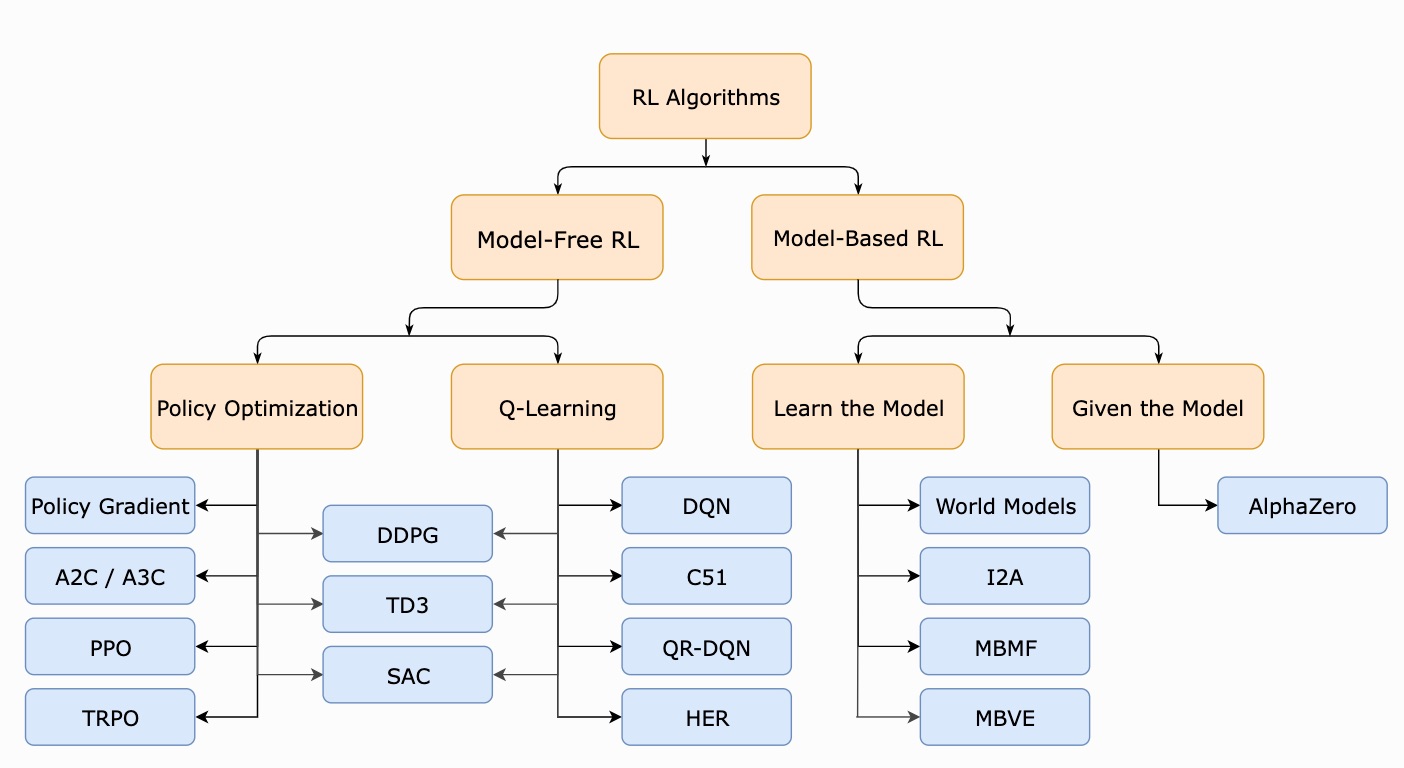
To start, let's first cover some of the basic components of RL. Markov Decision Processes (MDPs) form the mathematical foundation of RL. An MDP defines the environment as a set of states, actions, rewards, and transitions, where the next state depends only on the current state and action. This setup allows agents to learn optimal policies for decision-making under uncertainty.


(Model Free) Policy Optimization
*Policy Optimization* methods focus on directly improving the policy, which defines the agent's behavior. Common algorithms like REINFORCE, PPO (Proximal Policy Optimization), and Actor-Critic methods iteratively adjust the policy to maximize expected rewards. These techniques are effective in complex environments where learning a model of the environment is infeasible.
One of the better explanations of Policy Optimization I have seen.

(Model Free) Gradient Free
*Gradient-Free* methods, like evolutionary strategies and genetic algorithms, search for optimal policies without using gradient information. These methods are often used in RL when gradient-based optimization is challenging, such as in high-dimensional or non-differentiable environments. We will cover some of the breakthroughs and applications of these algorithms in another section of the site.



(Model Based) Learning the Model
In *Model-Based* RL, the agent learns a model of the environment's dynamics and uses it to plan actions. Algorithms like Dyna-Q integrate planning and learning by updating the model and generating simulated experiences, helping the agent to achieve faster convergence. When the *Model* is already provided or accurately approximated, planning algorithms like Value Iteration and Policy Iteration can be applied. These techniques use the model to compute an optimal policy without additional interaction, making them valuable in structured environments like simulations.


1.3.4 Additional Learning Techniques
There are other types of learning (meta learning, transfer learning, imitation learning)
1.4 Deep Learning
Deep Learning is a subset of machine learning that uses neural networks with many layers (hence "deep") to model complex patterns in large datasets. It's the backbone of advances in computer vision, natural language processing, speech recognition, and more. Deep learning has been transformative in AI, enabling systems to learn directly from data, often without needing human-defined features.
Artifical Neural Networks
Artificial Neural networks are computational models inspired by the human brain, consisting of layers of interconnected "neurons." Each neuron performs a weighted sum of inputs, applies an activation function, and passes the result to the next layer. These networks are trained through backpropagation, adjusting weights to minimize error in predictions.


Convolutional Neural Networks (CNNs)
CNNs are designed for processing structured grid data, like images. By using convolutional layers to detect spatial hierarchies (such as edges, shapes, and textures), CNNs are especially effective in image recognition and computer vision tasks.

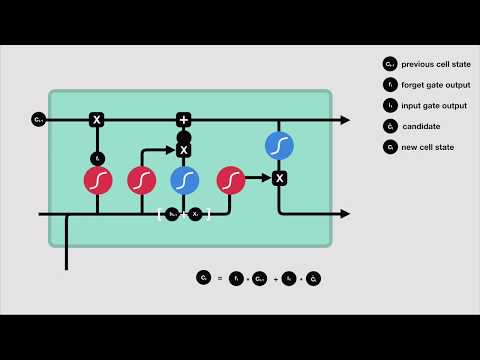
Recurrent Neural Networks (RNNs) and LSTMs
RNNs are specialized for sequential data, where each data point depends on previous points, making them suitable for time series and text data. Long Short-Term Memory networks (LSTMs) improve upon RNNs by addressing the issue of vanishing gradients, allowing them to capture long-term dependencies.
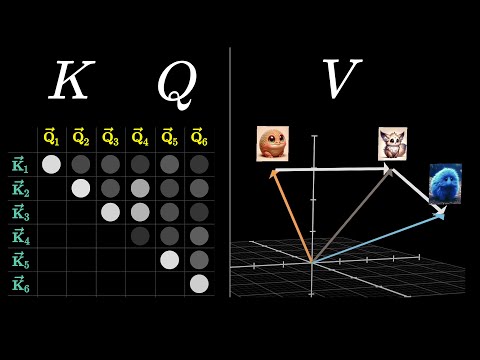
Transformers and Attention Mechanisms
Transformers are the foundation of modern natural language processing. They use an "attention" mechanism to weigh the importance of different words in a sequence, enabling models like GPT and BERT to understand language context and semantics on a large scale.

Generative Adversarial Networks (GANs)
GANs consist of two networks, a generator and a discriminator, competing against each other. The generator creates data, while the discriminator tries to distinguish between real and generated data. This approach is effective for creating realistic images, art, and synthetic data.


Autoencoders and Variational Autoencoders (VAEs)
Autoencoders are neural networks trained to compress and reconstruct data, often used for noise reduction, feature learning, and anomaly detection. Variational Autoencoders (VAEs) introduce a probabilistic approach, making them useful for generating new, unique data points.


Deep Learning Frameworks: TensorFlow and PyTorch
TensorFlow and PyTorch are two of the most popular deep learning frameworks, providing essential tools for building and training neural networks. TensorFlow, developed by Google, and PyTorch, by Facebook, each have strengths that make them suitable for different types of deep learning tasks.
In programming, frameworks are platforms that provide tools and structures to help build AI systems more easily. Libraries are collections of pre-written code that developers can use to perform specific tasks, like handling data or doing math. Packages are bundles of libraries and other tools, designed to make specific types of AI tasks, like image recognition or language processing, faster and more efficient. Together, these tools help developers build AI systems without starting from scratch.


Domains in AI
While Machine Learning (ML) and Deep Learning (DL) are technical approaches in AI, domains like Natural Language Processing (NLP) and Computer Vision (CV) represent application areas. These domains utilize ML and DL techniques to solve specific challenges, such as understanding language or recognizing images.
Natural Language Processing (NLP)
NLP is a field focused on enabling computers to understand, interpret, and generate human language. NLP techniques use ML and DL to perform tasks such as translation, sentiment analysis, and text summarization, making it crucial in applications like chatbots, search engines, and personal assistants.



Computer Vision (CV)
Computer Vision enables computers to interpret and process visual information from the world. By leveraging DL models like CNNs, CV applications can recognize objects, detect faces, and analyze scenes, making it essential for fields like robotics, medical imaging, and autonomous driving.


Speech Recognition
Speech Recognition involves transcribing spoken language into text. ML and DL models process audio signals to identify phonetic patterns, enabling applications like virtual assistants and automated transcription services to accurately understand and respond to voice commands.


Robotics
Robotics integrates AI with physical systems, enabling robots to perform complex tasks autonomously. Using ML and CV, robots can perceive their environment, make decisions, and act, making advancements possible in manufacturing, healthcare, and exploration.
